
Replication: Red
Replication
Perception
Consumer Behavior
Failedreplication



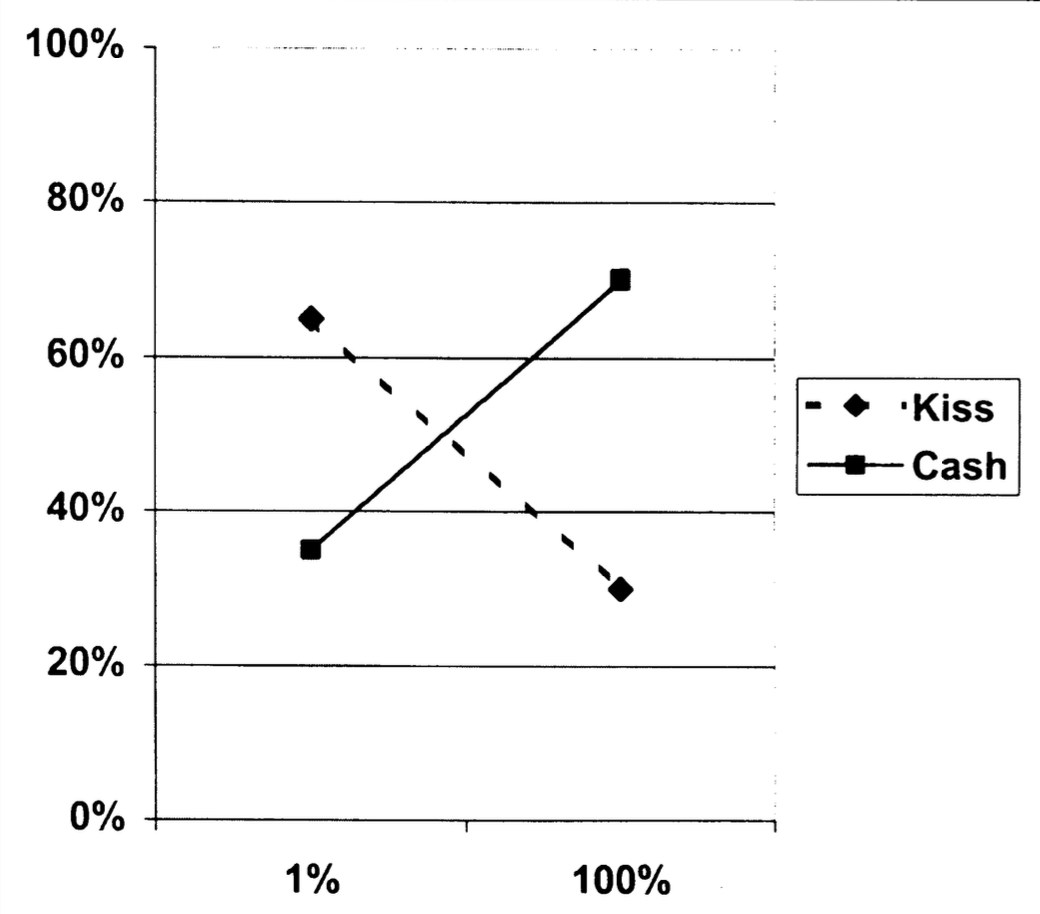
Replication: Default effect
Replication
Default Effekt
Framing
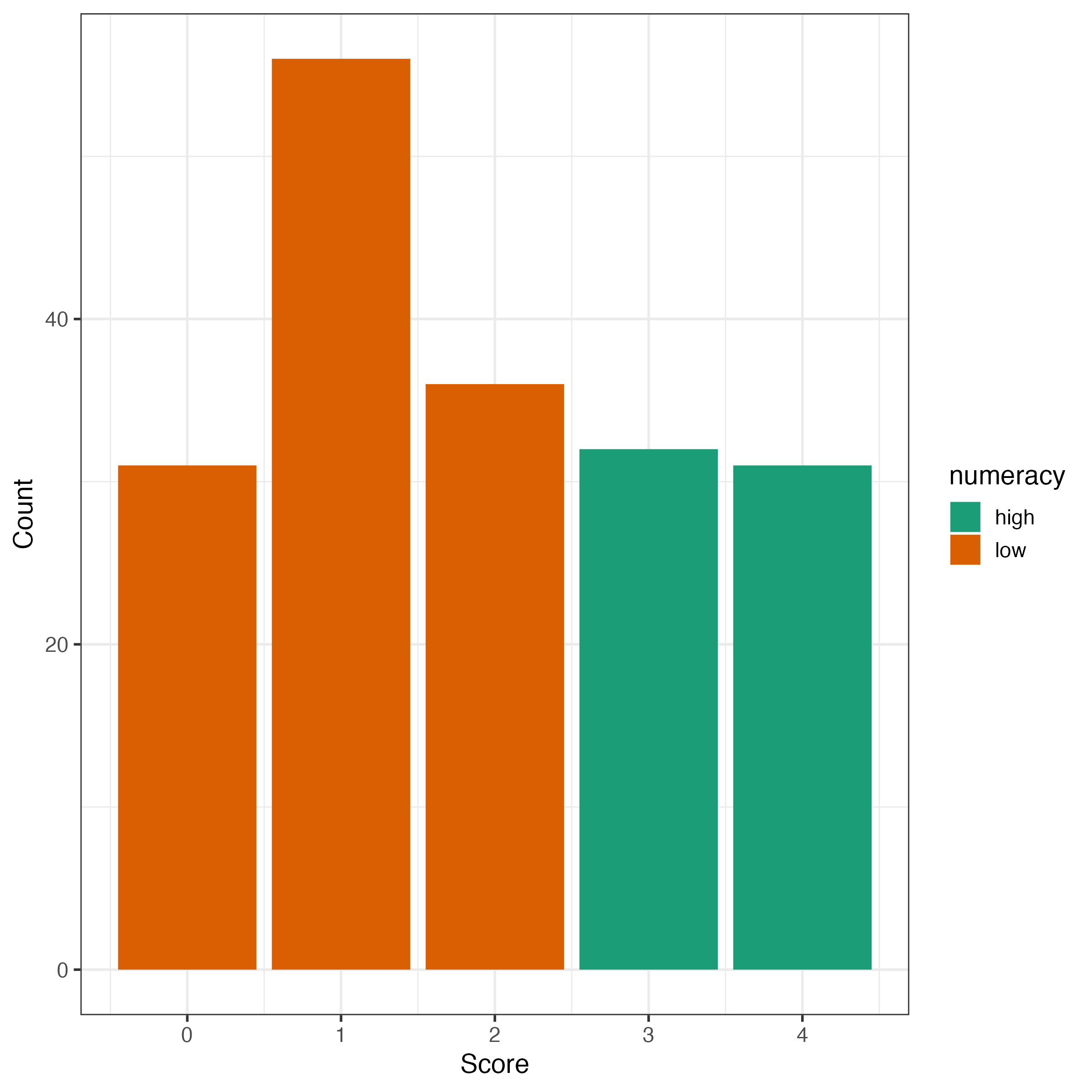
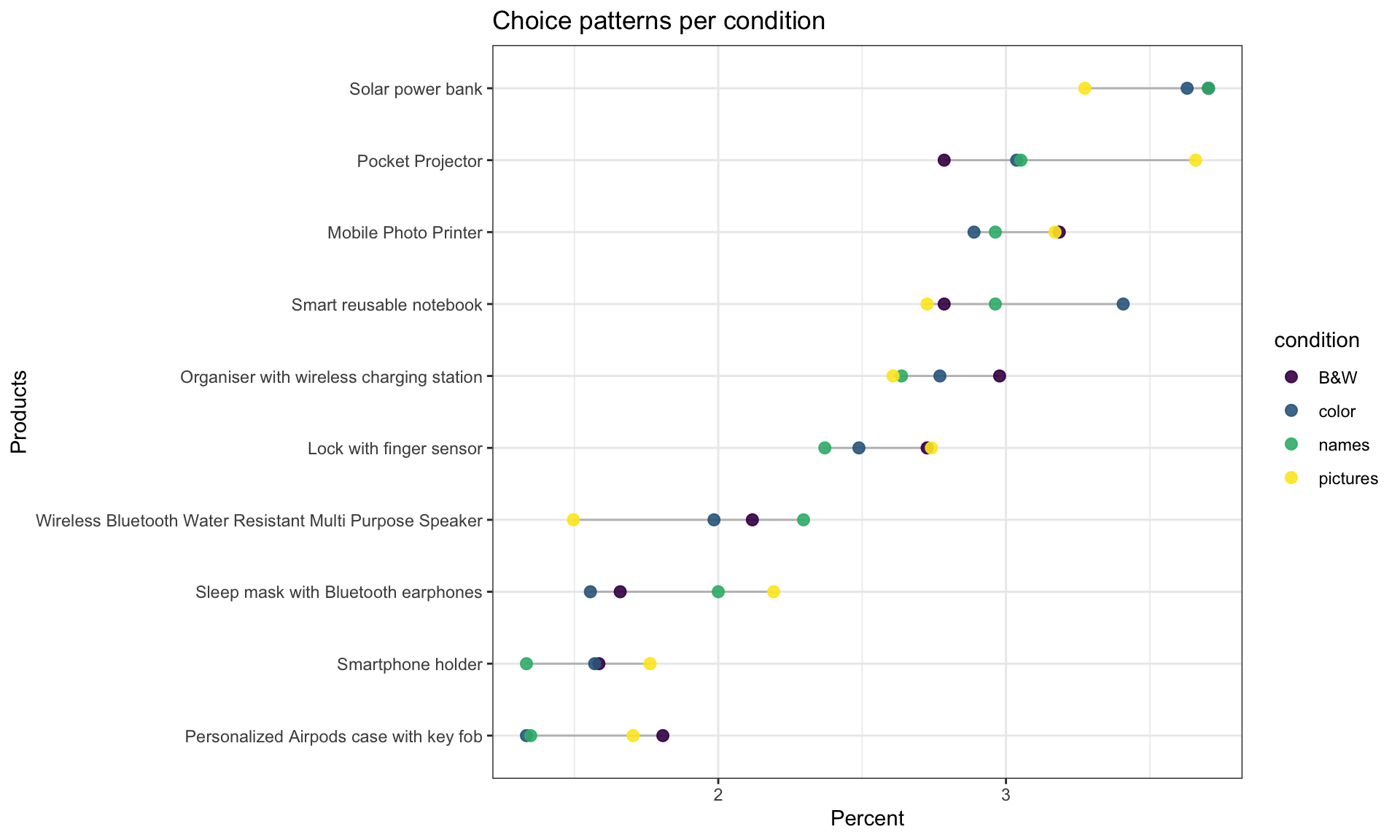


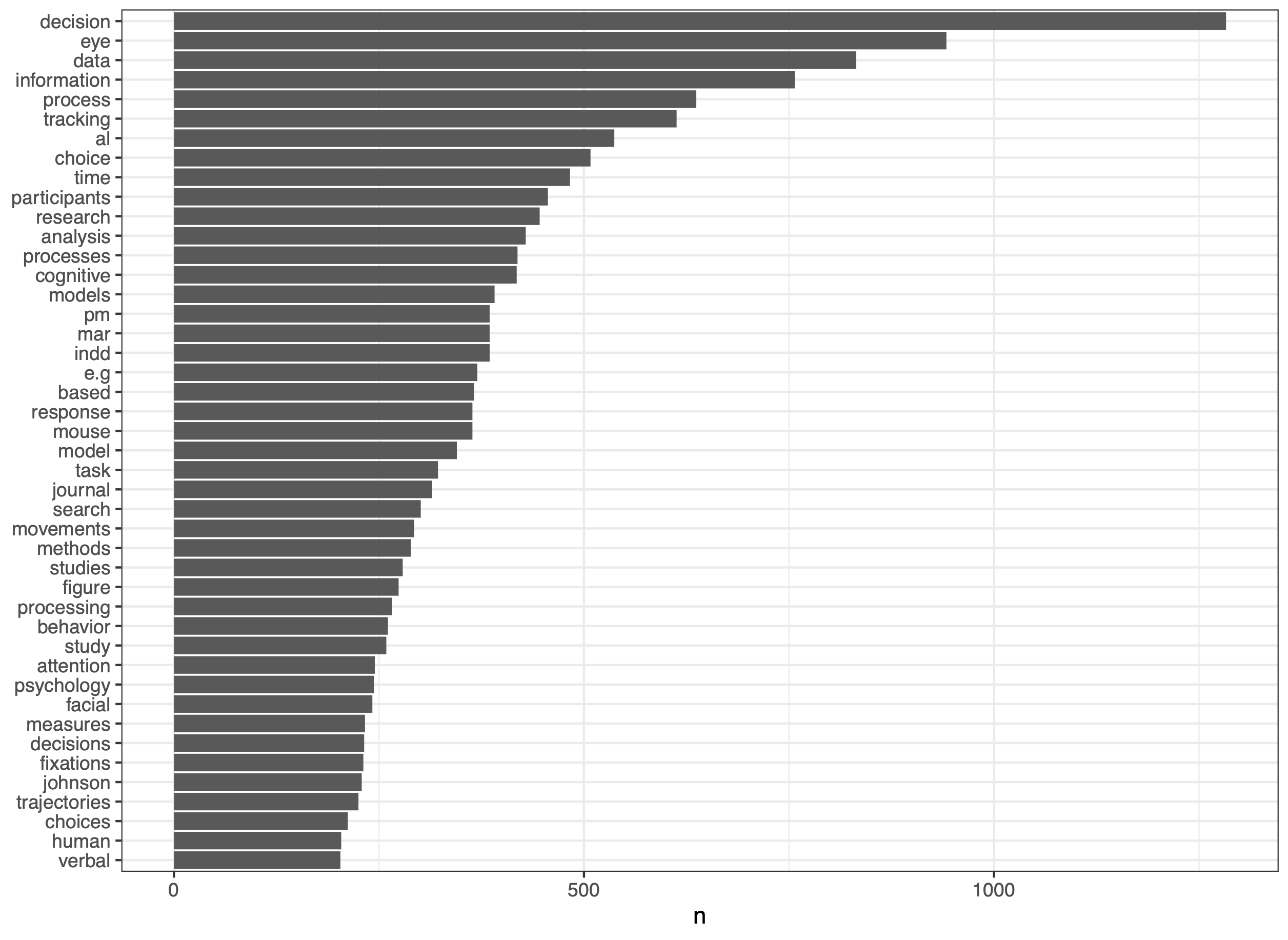
Handbook of Process Tracing Methods
Process tracing
Decision Making
Eye tracking
Flashlight
Mousetracking
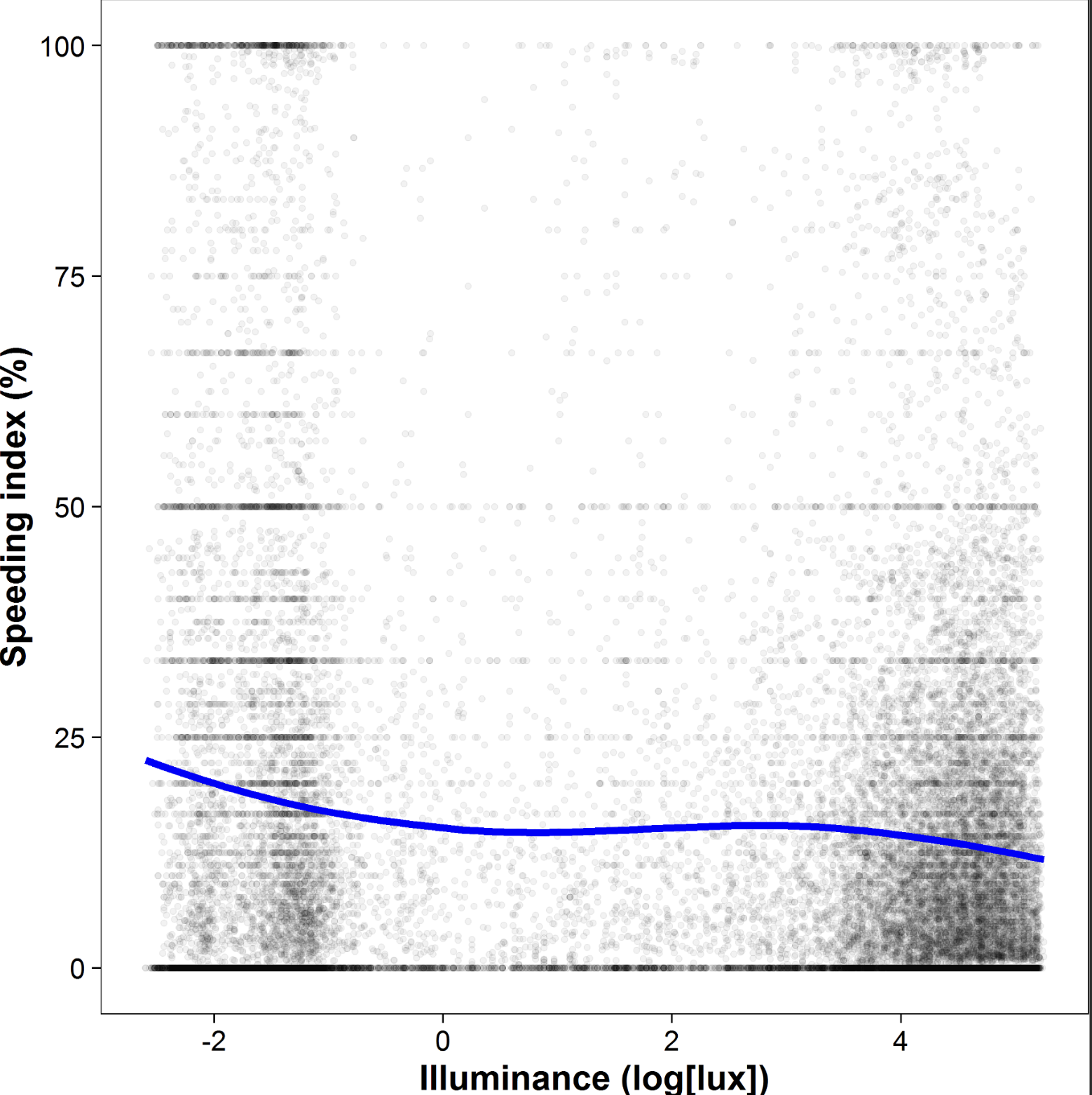
Professor priming - or not
Decision Making
Replication
RRR

Growing up to be old
Decision Making
Process tracing
Everything is fucked …
Ego depletion
Replication
Science
Teaching




Moving an idea into business
Decision Making
Flashlight
Open Source
Papers




No matching items